COMPUTER VISION AND PATTERN RECOGNITION (CVPR), 2020
Abstract
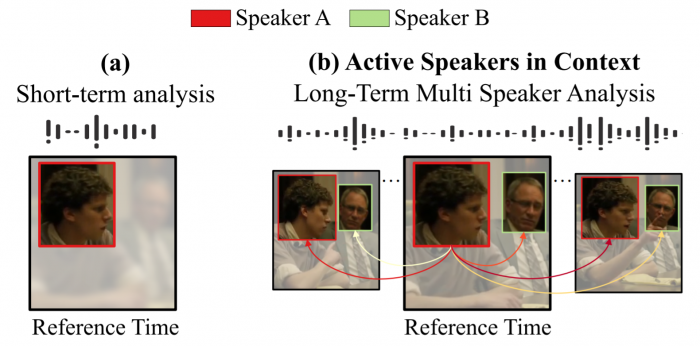
Current methods for active speak er detection focus on modeling short-term audiovisual information from a single speaker. Although this strategy can be enough for addressing single-speaker scenarios, it prevents accurate detection when the task is to identify who of many candidate speakers are talking. This paper introduces the Active Speaker Context, a novel representation that models relationships between multiple speakers over long time horizons. Our Active Speaker Context is designed to learn pairwise and temporal relations from an structured ensemble of audio-visual observations. Our experiments show that a structured feature ensemble already benefits the active speaker detection performance. Moreover, we find that the proposed Active Speaker Context improves the state-of-the-art on the AVA-ActiveSpeaker dataset achieving a mAP of 87.1%. We present ablation studies that verify that this result is a direct consequence of our long-term multi-speaker analysis.