International workshop on simulation and synthesis in medical imaging
Abstract
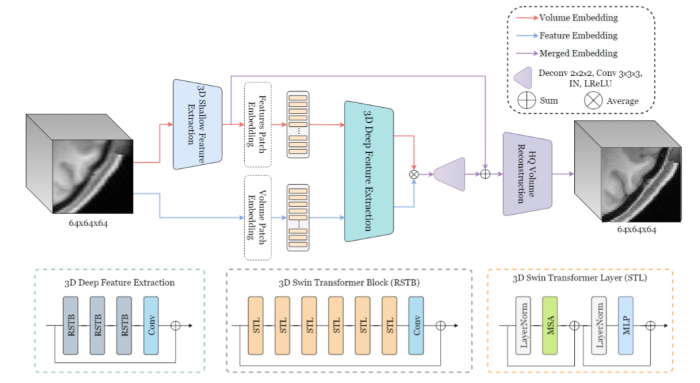
This paper presents a novel framework for processing volu-
metric medical information using Visual Transformers (ViTs). First, We
extend the state-of-the-art Swin Transformer model to the 3D medical
domain. Second, we propose a new approach for processing volumetric
information and encoding position in ViTs for 3D applications. We in-
stantiate the proposed framework and present SuperFormer, a volumet-
ric transformer-based approach for Magnetic Resonance Imaging (MRI)
Super-Resolution. Our method leverages the 3D information of the MRI
domain and uses a local self-attention mechanism with a 3D relative
positional encoding to recover anatomical details. In addition, our ap-
proach takes advantage of multi-domain information from volume and
feature domains and fuses them to reconstruct the High-Resolution MRI.
We perform an extensive validation on the Human Connectome Project
dataset and demonstrate the superiority of volumetric transformers over
3D CNN-based methods. Our code and pretrained models are available
at https://github.com/BCV-Uniandes/SuperFormer