Computer Vision and Image Understanding
Abstract
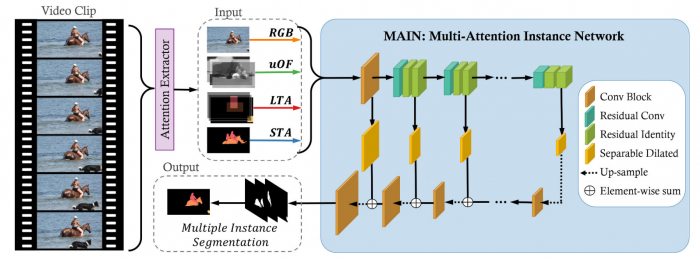
Instance-level video segmentation requires a solid integration of spatial and temporal information. However, current methods rely mostly on domain-specific information (online learning) to produce accurate instance-level segmentations. We propose a novel approach that relies exclusively on the integration of generic spatio-temporal attention cues. Our strategy, named Multi-Attention Instance Network (MAIN), overcomes challenging segmentation scenarios over arbitrary videos without modelling sequence- or instance-specific knowledge. We design MAIN to segment multiple instances in a single forward pass, and optimize it with a novel loss function that favors class agnostic predictions and assigns instance-specific penalties. We achieve state-of-the-art performance on the challenging Youtube-VOS dataset and benchmark, improving the unseen Jaccard and F-Metric by 6.8% and 12.7% respectively, while operating at real-time (30.3 FPS).