IMAGE AND VISION COMPUTING
Abstract
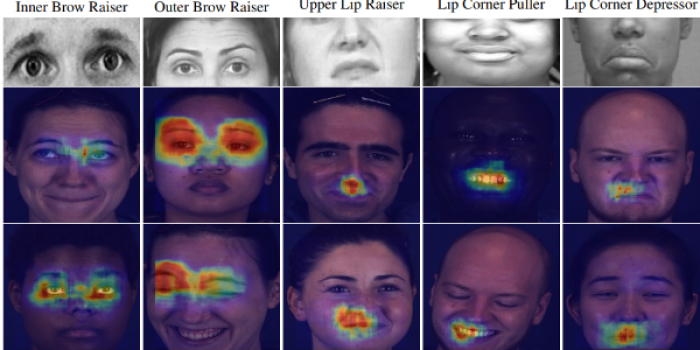
We propose a novel convolutional neural network approach to address the fine-grained recognition problem of multi-view dynamic facial action unit detection. We leverage recent gains in large-scale object recognition by formulating the task of predicting the presence or absence of a specific action unit in a still image of a human face as holistic classification. We then explore the design space of our approach by considering both shared and independent representations for separate action units, and also different CNN architectures for combining color and motion information. We then move to the novel setup of the FERA 2017 Challenge, in which we propose a multi-view extension of our approach that operates by first predicting the viewpoint from which the video was taken, and then evaluating an ensemble of action unit detectors that were trained for that specific viewpoint. Our approach is holistic, efficient, and modular, since new action units can be easily included in the overall system. Our approach significantly outperforms the baseline of the FERA 2017 Challenge, with an absolute improvement of 14% on the F1-metric. Additionally, it compares favorably against the winner of the FERA 2017 Challenge.