17TH INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV) WORKSHOPS, 2019
Abstract
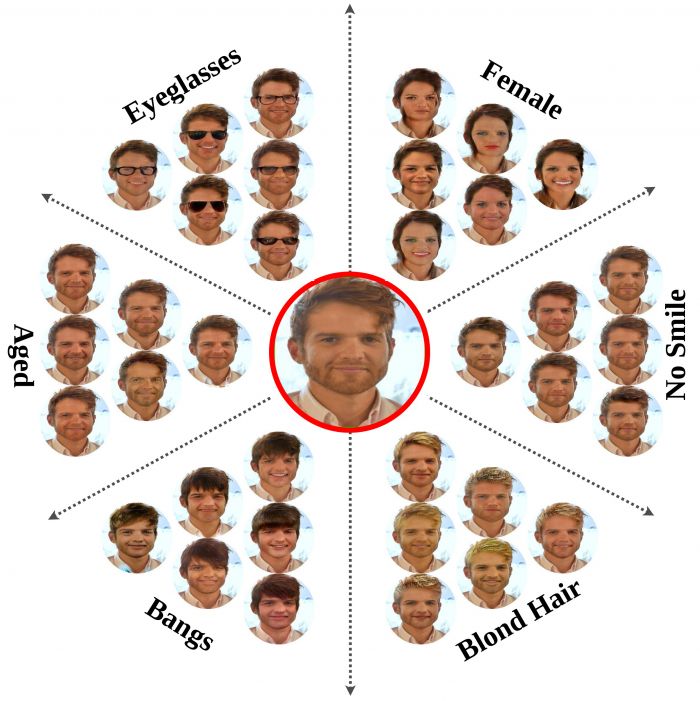
Cross-domain mapping has been a very active topic in recent years. Given one image, its main purpose is to translate it to the desired target domain, or multiple domains in the case of multiple labels. This problem is highly challenging due to three main reasons: (i) unpaired datasets, (ii) multiple attributes, and (iii) the multimodality (e.g., style) associated with the translation. Most of the existing state-of-the-art has focused only on two reasons, i.e. either on (i) and (ii), or (i) and (iii). In this work, we propose a joint framework (i, ii, iii) of diversity and multi-mapping image-to-image translations, using a single generator to conditionally produce countless and unique fake images that hold the underlying characteristics of the source image. Our system does not use style regularization, instead, it uses an embedding representation that we call domain embedding for both domain and style. Extensive experiments over different datasets demonstrate the effectiveness of our proposed approach in comparison with the state-of-the-art in both multi-label and multimodal problems. Additionally, our method is able to generalize under different scenarios: continuous style interpolation, continuous label interpolation, and fine-grained mapping. Code and pretrained models are available at this https URL.