Joint Workshop on Augmented Environments for Computer-Assisted Interventions (AE-CAI), Computer Assisted and Robotic Endoscopy (CARE), and OR 2.0 Context Aware Operating Theaters (OR2.0)
Abstract
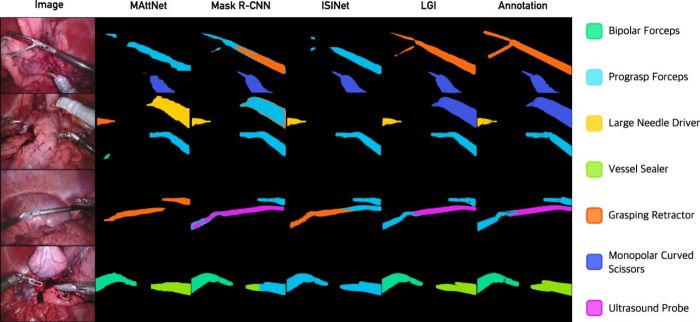
We present the first experimental framework for segmenting instruments in surgical scenes guided by natural language descriptions. Previous approaches rely exclusively on visual cues, thus ignoring the fine-grained nature of the problem. We exploit the rich domain knowledge of function by introducing structured descriptions. Our method, the Language-Guided Instrument (LGI) Segmentation network, merges three levels of information to compute the probability of an object candidate belonging to each surgical instrument category: context information (the image’s features), local information (the candidate’s features) and language information (a sentence per class), in which we include the differentiating details of each instrument type. We perform a comprehensive experimental evaluation over the standard benchmarks for the task and we show that LGI enhances the performance of different backbone instance segmentation methods, obtaining a significant improvement over the state-of-the-art. To the best of our knowledge, we propose the first experimental framework for jointly applying vision and language to a high-impact global healthcare problem.